Framework
The initial algorithm architecture and implementations has been discussed in the Slide2Lecture paper. In this section, we will
Briefly recap the algorithm framework introduced within the Slide2Lecture paper.
Discuss how such framework is implemented and formalized in our system deployment to support scaleble yet efficient deployment.
We also provide an version log for the infrastructure for those readers who are interested to trace the difference and how MAIC’s infra has evolved.
Algorithm Framework
The overall process can be divided into three stages, Read, Plan, and Teach.
Read and Plan stages are responsible for handling an input seed into extracted content and agenda and generating lecture plans (Functions) according to extracted contents via handling. These two together serves the lecture planning process. We formalize different teaching activities as different functions. We denote the type of the function as \(function.type\), and the values of the function to be stored in a dict instance denoted as, \(function.value\).
Teach stage provides the interactive learning process. According to the learning trajectory described within the Agenda and internal Functions, the teaching process is instanced as the ordered list of functions, where each function involves many ordered actions.
Implementation
Algorithm
As MAIC exists as a continue evolving system, we are certain that multiple versions of algorithm pipelines will be released.
We briefly introduce how each is achieved, however, pls be aware that the abstract introduction are lacking the details and intuitions which were presented in the original papers.
[Latest] Ver 1.0 Slide2Lecture
This pipeline provides tuning-free and gpu-free solution from input pptx file to outputing the interactive learning environment. It is also the initial version of the MAIC’s algorithm design.
Read
Content Extraction
We use libreoffice to convert a pptx file into a pdf file, we then use classic python packages to further convert the pdf file into png files. This is the Visual information \(v\).
We extract the text (all the texts in a slide page and the notes in the slide page) as the textual information, \(t\).
Structure Extraction
Description Generation. We take the current page’s textual and visual information, along with the description generated in the previous \(k\) pages, and ask the preclass LLM (set to be GPT4V) to output a description of the current page.
Slide File Segmentation. We take the desciptions of the slide pages and interactively generate the tree-formed agenda’s structure.
Plan
ShowFile
This is directly generated via code as the leaf nodes of the agenda tree are the pages of the input slide file.
ReadScript
This is generated in a similar manner as description generation but instead the preclass LLM is asked to output a script.
AskQuestion
This takes the scripts and finds the ending leaf-child-node of each agenda node. We limit this generation to only occur when the agenda node has atleast three childrens.
Teach
Teaching Action Queue
We employ DFS and
teachingActionQueue = list() for agenda_node in DFS(Agenda): teachingActionQueue.extend(agenda_node.functions)
Conflict Handling. In an online Intelligent Tutoring System, human teachers may revise the teaching plan when students are taking the lecture, this causes issues for how to update the teachingActionQueue, which becomes further critical when the teacher is revising the structure of the agenda. We handle this by instead lazy loading the next agenda_node’s functions only when all the functions in the queue are complete.
Lecture Interface/Process
We employ our special designed scene controller design, where different implementations of interaction management is practiced with different controllers(we refer to them as executor’s in code) for each Function type.
for function in teachingActionQueue: executor = FunctionList.get(function.type) create interaction actions via [executor(function.value)]
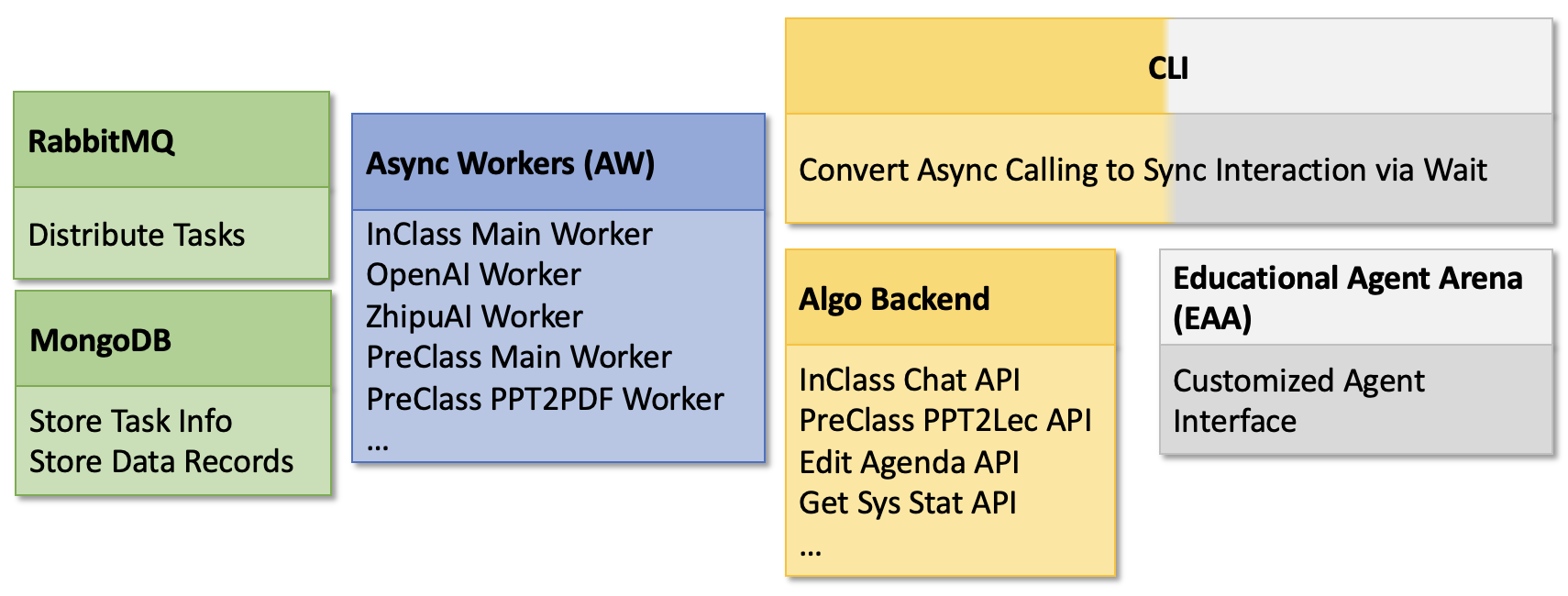
Scalable Infrastructure
Since MAIC aims to support the massive courses, it demands a scalable deployment. On the other hand, as a continue evolving system, we found that the algo team of MAIC demands decoupled implementation for a cleaner implementation and a commandline tool for debugging.
Catering such demands, MAIC implements each service as asynchronized workers for easy scaling, api backend for decoupled implementation and multiple tools for debugging:
Customized Deployment Script and Start-Up Data Dump
Command-Line Interface for InClass Interaction
This transforms the async worker interactions to sync interaction in a commandline without the deployment of a frontend
Educational Agent Arena for Customized Multi-Agents
This frontend interface supports comparison for customized design of agents. A user may
edit/addinteracting agents orrefinemeta/controller agents and compare the performance in two different setups.This frontend also supports Education Academics to conduct experiments.
How The Infrastructure Components Work Together?